PostgreSQL表和元组的组织方式
PostgreSQL表和元组的组织方式
上面讲过PostgreSQL的页大小为8K,这意味着堆文件大小最小为8K,且一定为8K的整数倍。对于PostgreSQL,单个堆文件的最大大小限制为1G,超过1G的表会被分成多个堆文件存储。
每一个8K的页面的结构如下图:
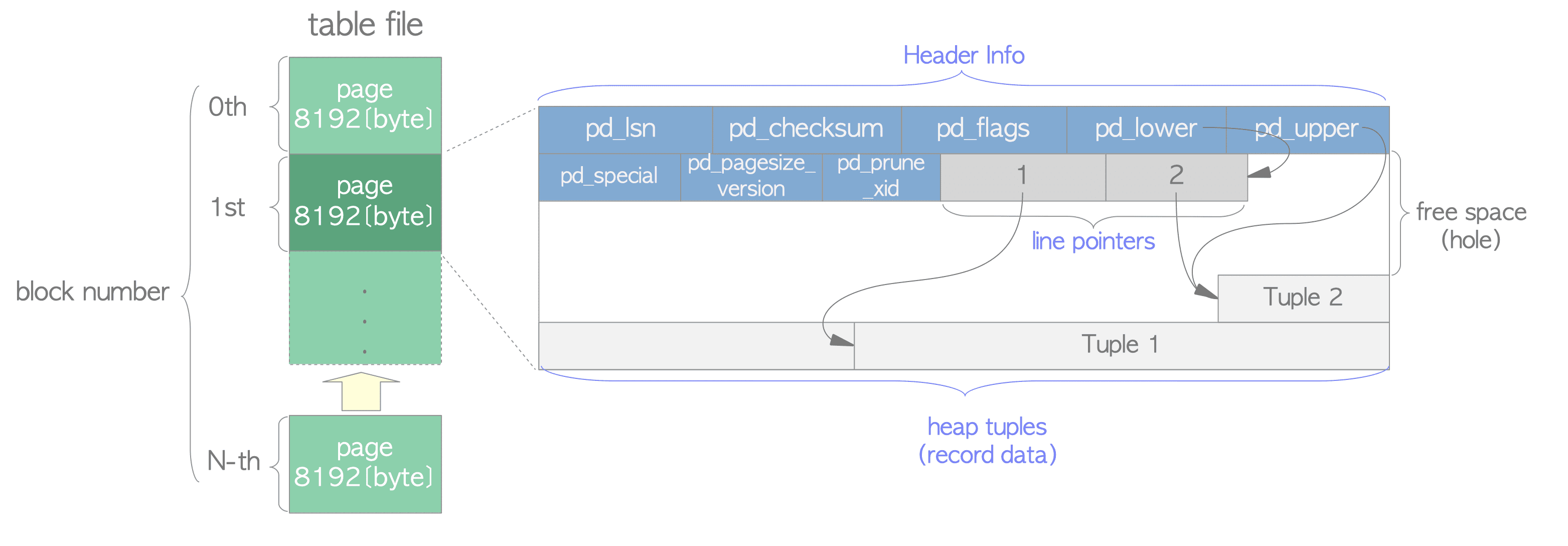
这里每一个tuple存储一条数据记录,从数据页底部开始向前依次存储,这些堆元组的地址由一个4B大小的行指针所指向。这些行指针内还保存了堆元组的长度,并形成一个简单的数组,扮演元组索引的角色。如需要定位某数据表中的一条记录,只需要知道该记录在堆文件中的页号和页面内的行指针偏移号即可。除此之外,每个页面的起始位置有大小为24B的页头,保存页面相关的元数据。行指针和尾部的tuple之间是该页面的空闲空间,大小超过2KB的堆元组会使用TOAST(The Oversized-Attribute Storage Technique,超大属性存储技术)来存储与管理。
Page指针
1
2
typedef char *Pointer;
typedef Pointer Page;
访问Page时会先将它加载到内存,所以Page可以仅用一个char *类型的指针来表示,指向内存中该Page的起始位置。由于Page的大小是已知的,通过Page指针和Page的大小即可表示并访问一个Page。在构建一个Page时,会调用PageInit函数进行初始化,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
void
PageInit(Page page, Size pageSize, Size specialSize)
{
// p指向Page的头部的起始位置,也是整个Page的起始位置
PageHeader p = (PageHeader) page;
// 对special区域的大小进行对齐
specialSize = MAXALIGN(specialSize);
// Page的大小应该为常量BLCKSZ(默认是8192)
Assert(pageSize == BLCKSZ);
// 除了头部和special区域外,Page内还应该有可用空间
Assert(pageSize > specialSize + SizeOfPageHeaderData);
// 将整个Page的内容填充为0
MemSet(p, 0, pageSize);
// 初始化Page头部的一些字段
p->pd_flags = 0;
p->pd_lower = SizeOfPageHeaderData;
p->pd_upper = pageSize - specialSize;
p->pd_special = pageSize - specialSize;
PageSetPageSizeAndVersion(page, pageSize, PG_PAGE_LAYOUT_VERSION);
/* p->pd_prune_xid = InvalidTransactionId; done by above MemSet */
}
页面头部
Page头定义在PageHeaderData结构体中,需要注意的是结构体尾部的行指针数组是一个0长度数组,又称为柔性数组(flexible array),不占用结构体大小。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
typedef struct PageHeaderData
{
PageXLogRecPtr pd_lsn; // Page最后一次被修改对应的xlog的标识
uint16 pd_checksum; // 校验和
uint16 pd_flags; // 标记位
LocationIndex pd_lower; // 空闲空间开始位置
LocationIndex pd_upper; // 空闲空间结束位置
LocationIndex pd_special; // 特殊空间开始位置
uint16 pd_pagesize_version; // 页面大小和版本号
TransactionId pd_prune_xid; // Page中可以修剪的最老元组的XID
ItemIdData pd_linp[FLEXIBLE_ARRAY_MEMBER]; // 行指针数组
} PageHeaderData;
typedef PageHeaderData *PageHeader;
pd_flags有以下几种情况:
1
2
3
4
5
#define PD_HAS_FREE_LINES 0x0001 // 是否有空闲的数据指针
#define PD_PAGE_FULL 0x0002 // 是否有空闲空间可供插入新的元组
#define PD_ALL_VISIBLE 0x0004 // 页内所有元组对所有人都可见
#define PD_VALID_FLAG_BITS 0x0007 // 以上所有有效标志位
行指针
行指针结构体内保存着Page中元组的位置和长度,通过一个行指针可以在Page中拿到相应的元组。
1
2
3
4
5
6
7
8
typedef struct ItemIdData
{
unsigned lp_off:15, // 元组的偏移量
lp_flags:2, // 行指针状态
lp_len:15; // 元组的长度
} ItemIdData;
typedef ItemIdData *ItemId;
其中lp_flags有以下四种取值:
1
2
3
4
#define LP_UNUSED 0 // 空闲行指针
#define LP_NORMAL 1 // 行指针被使用,指向一个元组
#define LP_REDIRECT 2 // HOT技术标识
#define LP_DEAD 3 // 行指针对应的元组为死元组
数据指针
对于一个元组,我们只需要知道它在文件中的页号和页内偏移量,就可以访问元组的数据。元组的全局数据指针定义在ItemPointerData结构体中:
1
2
3
4
5
typedef struct ItemPointerData
{
BlockIdData ip_blkid; // 文件内的块号
OffsetNumber ip_posid; // 页内行指针偏移量
}
元组
对于每一个页,由于长度是一个定值,我们只需要知道指向页起始位置和页长度即可,在内存中并没有将页构建成一个8K的结构体,而是直接用一个指针和一些宏定义访问、管理页。而对于元组来说,由于每个元组长度是可变的,且元组的大小远低于页,所以元组在内存中的表示形式是HeapTupleData结构体:
1
2
3
4
5
6
7
typedef struct HeapTupleData
{
uint32 t_len; // 元组长度
ItemPointerData t_self; // 元组的数据指针
Oid t_tableOid; // 元组所在表的Oid
HeapTupleHeader t_data; // 元组数据
} HeapTupleData;
这是元组在内存中的表示形式,而在Page中进行存储时,元组并不会有t_len、t_self和t_tableOid项,t_data才是元组本身在文件中的存储形式,这是一个HeapTupleHeader结构体:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
typedef struct HeapTupleFields
{
TransactionId t_xmin; // 插入此条记录的事务ID
TransactionId t_xmax; // 插入此条记录的事务ID,如未更改或未删除则为0
union
{
CommandId t_cid; // 插入、删除该元组的命令ID
TransactionId t_xvac; // VACUUM操作移动一个行版本的XID
} t_field3;
} HeapTupleFields;
struct HeapTupleHeaderData
{
union
{
HeapTupleFields t_heap;
DatumTupleFields t_datum;
} t_choice;
ItemPointerData t_ctid; // 当前版本或更新版本的TID
uint16 t_infomask2; // 一些属性和标识位
uint16 t_infomask; // 标识位
uint8 t_hoff; // 到用户数据的偏移量,表示元组头的大小
bits8 t_bits[FLEXIBLE_ARRAY_MEMBER]; // 元组中NULL值的列
// 结构体后面是元组数据本身
};
typedef struct HeapTupleHeaderData HeapTupleHeaderData;
typedef HeapTupleHeaderData *HeapTupleHeader;
对于t_choice字段,只有当新元组在内存中形成时才会用到DatumTupleFields,此时并不关心事务可见性,只需要记录元组长度等信息,而存储到堆文件中的Page页时,t_choice字段都应该为HeapTupleFields结构体。t_ctid字段就是一个上面提到的数据指针,记录它在文件中的页号和偏移量。t_bits也是一个柔性数组,当元组中没有空值的列时,不占用结构体大小。